
Authors:
(1) Nicholas Farn, Microsoft Corporation {Microsoft Corporation {nifarn@microsoft.com};
(2) Richard Shin, Microsoft Corporation {eush@microsoft.com}.
Table of Links
Conclusion, Reproducibility, and References
D. Nuances comparing prior work
5 RELATED WORK
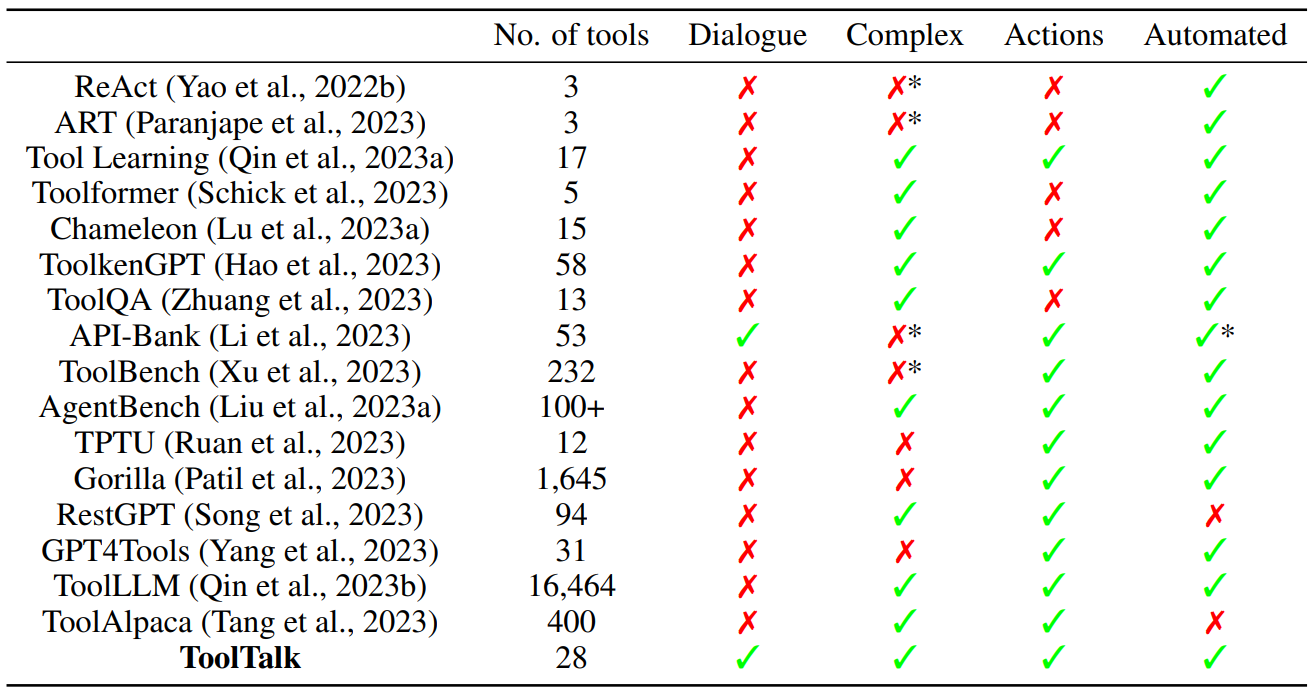
In Section 1, we described our desired criteria for evaluating tool-using LLM-based assistants: using dialogue to specify intents requiring multi-step tool invocations, and actions rather than only retrieving information, for a fully automated evaluation not requiring human judgement over the outputs of the system under test. Table 5 summarizes how other work about evaluating tool-using LLMs compares along these factors. We describe the related work in greater detail below.
Tool-augmented LLMs are also known as tool-augmented learning, tool LLMs, tool-learning, augmented language models (ALMs), or tool manipulation with LLMs (Xu et al., 2023; Mialon et al., 2023; Qin et al., 2023a). Development in this area consists of improving LLM performance in traditional tasks by giving them access to tools such as a calculator or search engine (Lu et al., 2023a; Yao et al., 2022b; Paranjape et al., 2023; Hao et al., 2023). It can also include applying LLMs to traditional automation tasks such as embodied robotics or browsing the web (Liu et al., 2023b; Deng et al., 2023; Yao et al., 2022a; Liang et al., 2023), dubbed “LLM-as-agent” by AgentBench (Liu et al., 2023a).
Traditional tasks that tool-augmented LLMs have been applied to include question answering such as ScienceQA (Saikh et al., 2022) or HotPotQA (Yang et al., 2018), mathematical reasoning (Cobbe et al., 2021; Lu et al., 2023b; Qiao et al., 2023), multilingual translation and QA (Lewis et al., 2020; Scarton et al., 2019), open-domain QA (Zhu et al., 2021), and commonsense QA (Talmor et al., 2019) to name a few. These tasks are useful for demonstrating the benefits of augmenting LLMs with tool usage, but fail to fully distinguish how much LLMs rely on internal knowledge vs good usage of tools (Zhuang et al., 2023). They also fail to incorporate the use of tools that affect the external world since they are unnecessary for those tasks.
Common agent benchmarks that have been applied to tool-augmented LLMs include WebShop (Yao et al., 2022a), Tabletop (Liang et al., 2023), Mind2Web (Deng et al., 2023), and ALFWorld (Shridhar et al., 2020). Additionally, AgentBench compiles Mind2Web, WebShop, and ALFWorld into a unified benchmark while adding additional agent environments such as interacting with a bash terminal, creating SQL commands to query a database, interacting with a knowledge graph, digital card game simulations, and lateral thinking puzzles (Liu et al., 2023a). ToolBench does something similar by compiling Tabletop and Webshop while introducing a variety of other tasks consisting of predicting a single API call. These benchmarks are useful for evaluating the effectiveness of tool-augmented LLMs in a variety of autonomous situations. However, none of them test tool-augmented LLMs in a conversational setting. Furthermore, tasks in these benchmarks consist of issuing a single utterance which an agent then tries to accomplish without any further human interaction. This is in contrast to ToolTalk, where a conversation will consist of multiple utterances with multiple intermediary tasks.
Past works have also created datasets for evaluating tool-augmented LLM-based assistants. Examples include ToolLLM (Qin et al., 2023b), API-Bank (Li et al., 2023), TPTU (Ruan et al., 2023), Gorilla (Patil et al., 2023), RestGPT (Song et al., 2023), GPT4Tools (Yang et al., 2023), and ToolAlpaca (Tang et al., 2023) among others. Unfortunately, many of these datasets require manual inspection of the outputs of the assistant under test to perform a complete evaluation. A lot of them also have unrealistic queries, and do not reflect questions or intents humans are likely to say in real life.[4] Many of them are also simple, where the solution requires one or two tool calls (Li et al., 2023; Ruan et al., 2023; Yang et al., 2023; Tang et al., 2023). Except for Li et al. (2023), these consider users’ utterances in isolation rather than as part of a conversation or dialogue.
There also exists a corpus of work on task-oriented dialogue systems. This area of research is focused on collecting realistic, task-oriented dialogue for the tasks of intent classification and slot filling (Larson & Leach, 2022). Some popular task-oriented dialogue datasets include MultiWoz (Budzianowski et al., 2018), Taskmaster and TicketTalk (Byrne et al., 2019; 2020), and STAR and STARv2 (Mosig et al., 2020; Zhao et al., 2022). The goals of creating realistic dialogue and evaluating on intent classification and slot filling have some overlap with ToolTalk. However, taskoriented dialogue datasets usually only predict a single intent per user utterance, do not simulate plugins or tools, and do not provide execution feedback for predicted tool calls. TicketTalk (Byrne et al., 2020) is notable in that it does provide a simulation of a movie booking API, however this API does not provide execution feedback and is not rigorously defined allowing for loose arguments like “here” or “now”.
This paper is available on arxiv under CC 4.0 license.
[4] We include a few examples from various papers in Appendix C.