

Authors:
(1) Bobby He, Department of Computer Science, ETH Zurich (Correspondence to: bobby.he@inf.ethz.ch.);
(2) Thomas Hofmann, Department of Computer Science, ETH Zurich.
Table of Links
Simplifying Transformer Blocks
Discussion, Reproducibility Statement, Acknowledgements and References
A Duality Between Downweighted Residual and Restricting Updates In Linear Layers
4 SIMPLIFYING TRANSFORMER BLOCKS
We now describe how we arrive at our simplest Transformer block, Fig. 1 (top right), starting from the Pre-LN block, using a combination of signal propagation theory and empirical observations. Each subsection here will remove one block component at a time without compromising training speed, and we aim to provide an intuitive account of our progress in simplifying the Pre-LN block.
All experiments in this section use an 18-block 768-width causal decoder-only GPT-like model on the CodeParrot dataset,[1] which is sufficiently large that we are in a single epoch regime with minimal generalisation gap (Fig. 2), allowing us to focus on training speed. We provide depth scaling, and non-causal encoder-only, experiments, in Sec. 5. We use a linear decay learning rate (LR) schedule[2] with AdamW (Loshchilov & Hutter, 2017), with linear warmup for the first 5% steps. The maximum LR is tuned on training loss, using a logarithmic grid. Additional experimental details are in App. D.
4.1 REMOVING THE ATTENTION SUB-BLOCK SKIP CONNECTION
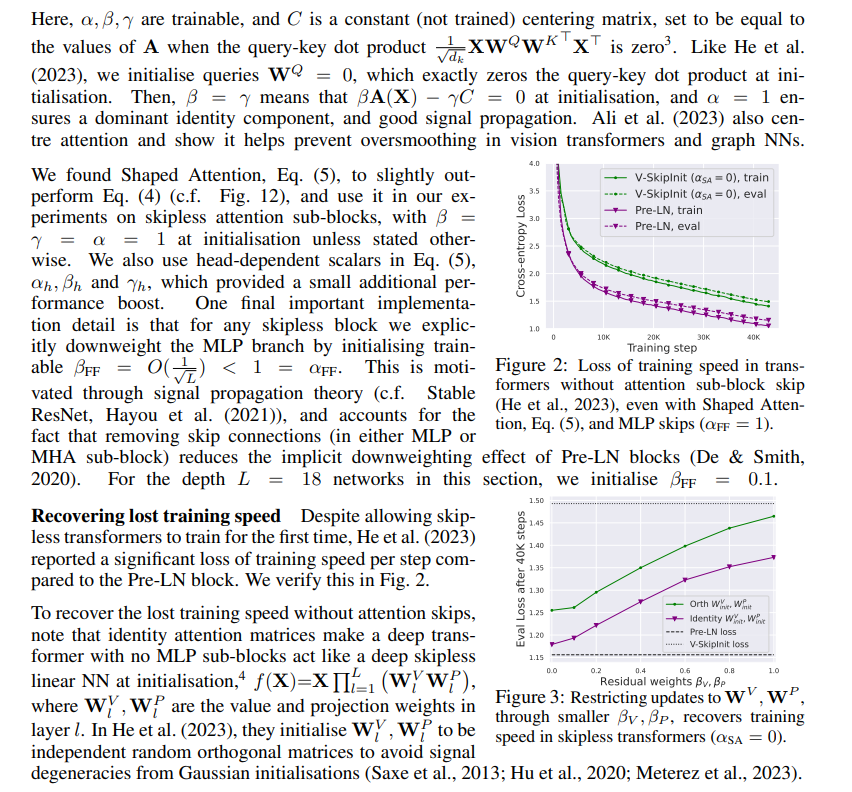
We first consider removing the skip connection in the attention sub-block. In the notation of Eq. (1), this corresponds to fixing αSA to 0. Naively removing the attention skip leads to a signal degeneracy called rank collapse (Dong et al., 2021), which causes poor trainability (Noci et al., 2022).
Setup He et al. (2023) outline modifications needed to the self-attention mechanism in order to correct these signal degeneracies at large depths, and train such deep skipless networks for the first time. One method they introduce, Value-SkipInit, modifies the self-attention matrix to compute:


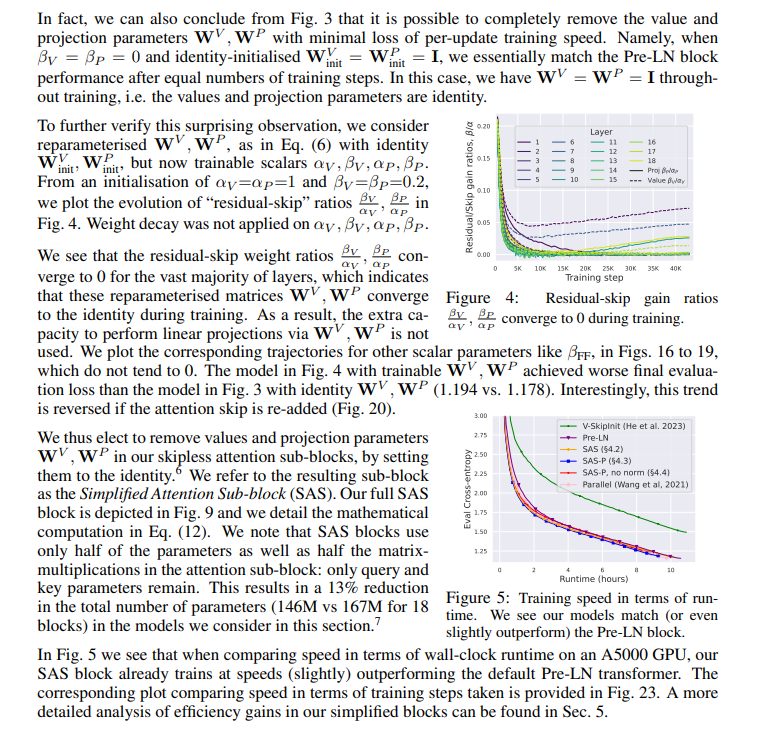
4.2 REMOVING VALUE AND PROJECTION PARAMETERS

4.3 REMOVING THE MLP SUB-BLOCK SKIP CONNECTION
So far we have simplified the Pre-LN transformer block by removing, without loss of training speed, three key components: 1) the attention sub-block skip connection, as well as 2) value and 3) projection matrices. We next turn to removing the remaining skip connection in the MLP sub-block.
This proved more challenging. Like previous works (Martens et al., 2021; Zhang et al., 2022; He et al., 2023), we found that making activations more linear, motivated through signal propagation, still resulted in a significant loss of per-update training speed without MLP skips when using Adam, as shown in Fig. 22. We also experimented with variants of the Looks Linear initialisation (Balduzzi et al., 2017), with Gaussian, orthogonal or identity weights, to no avail. As such, we use standard activations (e.g. ReLU in this section) and initialisations in the MLP sub-block throughout our work.

4.4 REMOVING NORMALISATION LAYERS
The final simplification we consider is removing normalisation layers, which leaves us with our simplest block (Fig. 1, top right). From a signal propagation initialisation perspective, it has been possible to remove normalisation at any stage of our simplifications in this section: the idea is that normalisation in Pre-LN blocks implicitly downweights residual branches, and this beneficial effect can be replicated without normalisation by another mechanism: either explicitly downweighting residual branches when skips are used, or biasing attention matrices to the identity/transforming MLP non-linearities to be “more” linear otherwise. As we account for these mechanisms in our modifications (e.g. downweighted MLP βFF & Shaped Attention), there is no need for normalisation.
Of course, these modifications have effects on training speeds and stability beyond initialisation, which are harder to predict from existing theory alone. In Fig. 5 we see that removing normalisation allows even our simplest transformer block, which does not have skips, sequential sub-blocks, values, projections or normalisations, to match the training speed of the Pre-LN block in terms of runtime. Having said that, we do observe a slight degradation in training speed per iteration, as seen in Fig. 23, suggesting that normalisation layers have some beneficial properties for training speed beyond what is captured by signal propagation theory. We thus treat our SAS (Fig. 9) and SAS-P (Fig. 10) blocks, with normalisation, as our main approaches. On this note, we point out that Dehghani et al. (2023) found extra normalisation on the queries and keys to provide improved training stability in ViT-22B, going against the recent trend of researchers seeking to remove normalisation.
This paper is available on arxiv under CC 4.0 license.
[1] Our setting is taken from https://huggingface.co/learn/nlp-course/chapter7/6.
[2] We found linear decay to slightly outperform cosine decay for both our models and baselines (c.f. Fig. 11).
[3] For example, when there is no masking, C becomes the uniform T × T stochastic matrix: 1 T 11⊤
[4] We set aside the MLP sub-block here for simplicity, but point out that all of our experiments use MLPs so our findings carry over to the full setting.
[5] Although the initial forward pass is identical regardless of βV , due to zero initialised ∆WV