

Authors:
(1) Toshit Jain, Indian Institute of Science Bangalore, India;
(2) Varun Singh, Indian Institute of Science Bangalore, India;
(3) Vijay Kumar Boda, Indian Institute of Science Bangalore, India;
(4) Upkar Singh, Indian Institute of Science Bangalore, India;
(5) Ingrid Hotz, Indian Institute of Science Bangalore, India and Department of Science and Technology (ITN), Linköping University, Norrköping, Sweden;
(6) P. N. Vinayachandran, Indian Institute of Science Bangalore, India;
(7) Vijay Natarajan, Indian Institute of Science Bangalore, India.
Table of Links
- Abstract and Intro
- Ocean data
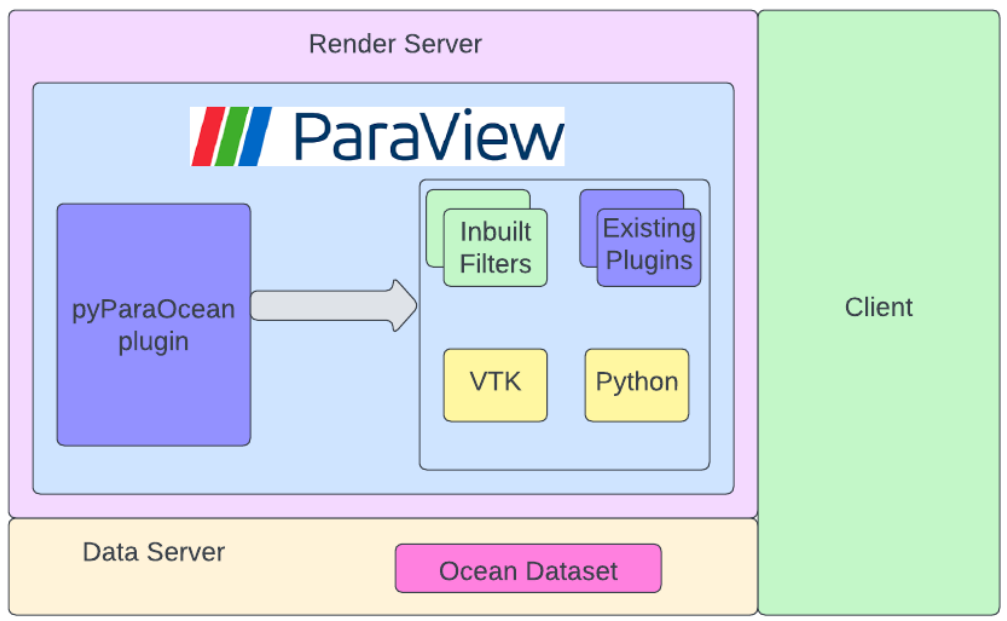
- pyParaOcean: Architecture
- pyParaOcean: Functionalities
- Case study: Bay of Bengal
- Conclusion
- Acknowledgments and References
2. Ocean data
Oceanographers typically deal with large multivariate spatiotemporal datasets – time-varying scalar or vector fields over a three dimensional region. The data is generated using simulations, satellite imagery, sensors on buoys, or in-situ physical observations. With strides in high performance computing, higher resolution sampling, and the increasing number of observables, the size of such datasets is rapidly increasing. Reanalysis datasets combine a numerical simulation model with observational inputs to furnish data that is spatio-temporally consistent. Ocean data contains strong temporal and spatial processes involving complex interactions between multi-scale entities [XLWD19]. It is analyzed on a variety of scales, from small-scale features such as eddies and fronts, to large-scale features such as ocean basins and circulation patterns.
All visualizations in this paper are generated using two datasets, the Red Sea and Bay of Bengal.
Red Sea: This dataset [TZG∗ 17] was made available as a part of the IEEE SciVis 2020 contest. It is a 50 member ensemble of threedimensional scalar and velocity fields. The data is regularly sampled on a 500 × 500 × 50 grid over 60 time steps covering a whole month of simulation time. Ensembles are the outputs of the simulated models with different parameters and initial conditions, and they may vary significantly even with a small change in parameter values. The members are the forecasts from MITgcm setups configured for the 30◦E - 50◦E and 10◦N - 30◦N domain that spans the entire Red Sea. They are implemented in Cartesian coordinates with a horizontal resolution of 0.04◦ × 0.04◦ (4 km) and 50 vertical layers, with a surface spacing of 4 m and a bottom spacing of 300 m. The dataset is available in the NetCDF format.
Bay of Bengal: This dataset is generated by a reanalysis product and available from the Nucleus for European Modelling of the Ocean (NEMO) repository [Mad08], with a daily resolution spanning the months of July-August 2020, a total of 62 time steps. The data is available in NetCDF format, with a 1/12◦ latitude-longitude resolution. Salinity measurements are available at 50 vertical levels, ranging from 1 m resolution near the surface to 450 m resolution towards the sea floor, including 22 samples in the upper 100 m. The Bay of Bengal, a geographical region confined by longitudes 75◦E and 96◦E and latitudes 5◦ S to 30◦N, with depth up to 200 m, is extracted from this data.
This paper is available on arxiv under CC 4.0 license.