

Authors:
(1) Michael Moor, Department of Computer Science, Stanford University, Stanford, USA and these authors contributed equally to this work;
(2) Qian Huang, Department of Computer Science, Stanford University, Stanford, USA and these authors contributed equally to this work;
(3) Shirley Wu, Department of Computer Science, Stanford University, Stanford, USA;
(4) Michihiro Yasunaga, Department of Computer Science, Stanford University, Stanford, USA;
(5) Cyril Zakka, Department of Cardiothoracic Surgery, Stanford Medicine, Stanford, USA;
(6) Yash Dalmia, Department of Computer Science, Stanford University, Stanford, USA;
(7) Eduardo Pontes Reis, Hospital Israelita Albert Einstein, Sao Paulo, Brazil;
(8) Pranav Rajpurkar, Department of Biomedical Informatics, Harvard Medical School, Boston, USA;
(9) Jure Leskovec, Department of Computer Science, Stanford University, Stanford, USA.
Table of Links
6 Discussion, Acknowledgments, and References
5 RESULTS
In our experiments, we focus on generative medical visual question answering (VQA). While recent medical VLMs predominantly performed VQA in a non-generative but rather discriminative manner (i.e., by scoring different answer choices), we believe that this ex-post classification to carry less clinical usefulness, than directly generating responses. On the other hand, generative VQA is more challenging to evaluate, as automated metrics suffer from significant limitations as they do not fully capture the domain-specific context. Thus, we perform a human evaluation study where clinical
experts review model generations (blinded) and score them (between 0 and 10) in terms of clinical usefulness.
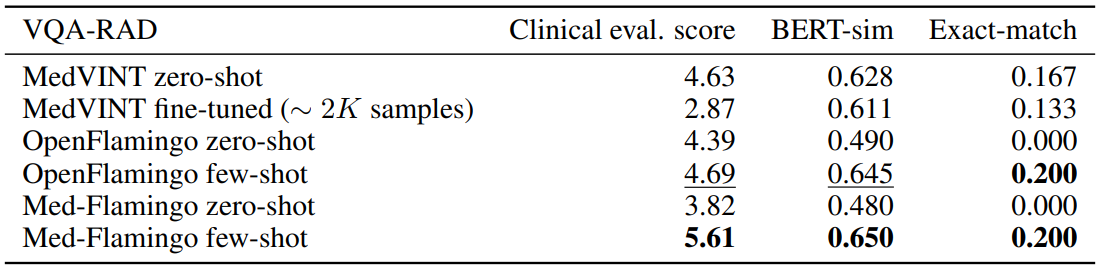
Conventional VQA datasets Table 1 shows the results for VQA-RAD, the radiological VQA dataset for which we created custom splits to address leakage (see Section4). Med-Flamingo few-shot shows strong results, improving the clinical eval score by ∼ 20% over the best baseline. In this dataset, the auxiliary metrics are rather aligned with clinical preference. Finetuning the MedVINT baseline did not lead to improved performance on this dataset which may be due to its small size. MedVINT zero-shot outperforms the other zero-shot ablations which may be partially attributed to its instruction tuning step on PMC-VQA.
Table 2 shows for the results for Path-VQA, the pathology VQA dataset. Compared to the other datasets, all models overall perform poorer on the Path-VQA dataset in terms of clinical evaluation score. We hypothesize that this has to do with the fact the models are not pre-trained on actual
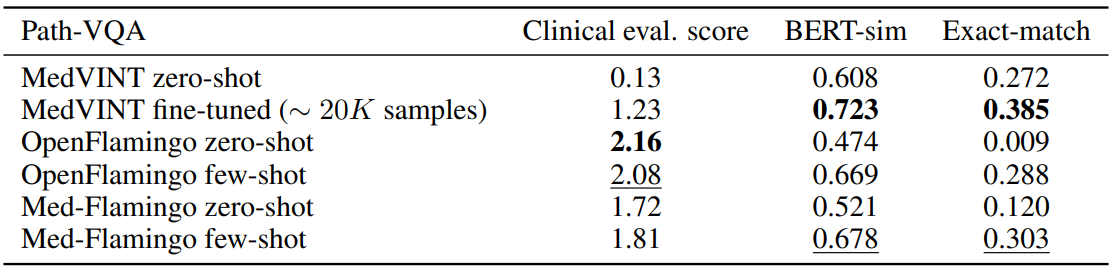
large-scale and fine-grained pathology image datasets, but only on a rather small amount of pathology literature (which may not be enough to achieve strong performance). For instance, Figure 3 shows that only a small fraction of our training data covers pathology. In the automated metrics (BERT-sim and exact-match), Med-Flamingo improves upon the OpenFlamingo baseline, however the overall quality does not improve (as seen in the clinical evaluation score). MedVINT was fine-tuned on a sizeable training split which results in strong automated metrics, but did not result in a clinical evaluation score that matches any Flamingo variant.
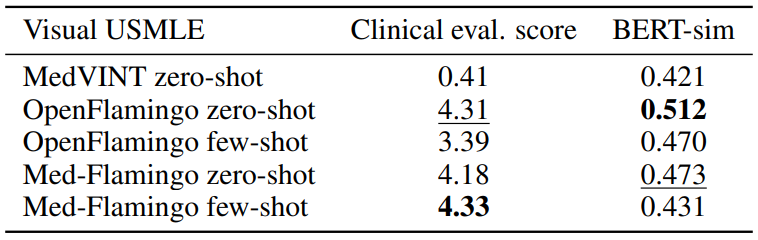
Visual USMLE Table 3 shows the results for the Visual USMLE dataset. Med-Flamingo (fewshot) results in the clinically most preferrable generations, whereas OpenFlamingo (zero-shot) is a close runner-up. As the ground truth answers were rather lengthy paragraphs, exact match was not an informative metric (constant 0 for all methods). The few-shot prompted models lead to lower automated scores than their zero-shot counterparts, which we hypothesize has to do with the fact that the USMLE problems are long (long vignettes as well as long answers) which forced us to summarize the questions and answers when designing few-shot prompts (for which we used GPT-4). Hence, it’s possible that those prompts lead to short answers that in terms of BERT-sim score may differ more from the correct answer than a more wordy zero-shot generation.
Across datasets Overall, we find that Med-Flamingo’s multimodal in-domain few-shot learning abilities lead to favorable generative VQA performance, leading to the lowest average rank of 1.67 in terms of clinical evaluation score as averaged across all evaluation datasets. As runner-up, OpenFlamingo zero-shot achieves a rank of 2.33.
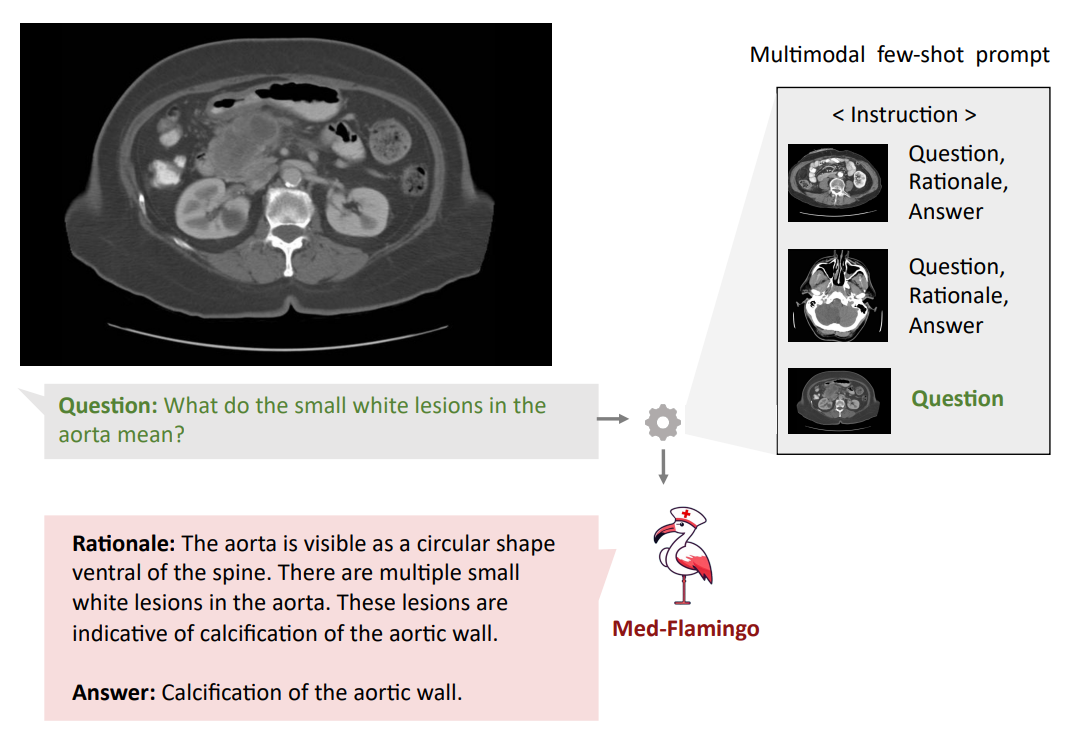
Qualitative analysis Finally, we showcase few examples of Med-Flamingo generations in more detail in Figures 1,5, and 6. Figure 5 exemplifies that a medical few-shot learner like Med-Flamingo can be prompted to generate rationale for its VQA answer. The shown example is impressive in that the rationale is visually guiding the reader towards the object of interest (calcification of the aortic wall). We note, however, that at this stage, few-shot multimodal prompted rationales may not be robust, especially when a model arrives at a wrong answer.
Figures 1 and 6 showcase two example problems from the Visual USMLE dataset. The problem descriptions were slightly rephrased and summarized using GPT-4 for display. In Figure 6, MedFlamingo generates the correct answer while not mentioning the underlying diagnosis (urothelial

cancer) as it was not asked for. By contrast, we observed baselines to directly diagnose the patient (instead of answering the actual question in a targeted way). The problem in Figure 1 illustrates that Med-Flamingo has the ability to integrate complex medical history information together with visual information to synthesize a comprehensive diagnosis that draws from the information of both modalities.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.