
Introduction
Managing streaming data from a source system, like PostgreSQL, MongoDB or DynamoDB, into a downstream system for real-time search and analytics is a challenge for many teams. The flow of data often involves complex ETL tooling as well as self-managing integrations to ensure that high volume writes, including updates and deletes, do not rack up CPU or impact performance of the end application.
For a system like Elasticsearch, engineers need to have in-depth knowledge of the underlying architecture in order to efficiently ingest streaming data. Elasticsearch was designed for log analytics where data is not frequently changing, posing additional challenges when dealing with transactional data.
Rockset, on the other hand, is a cloud-native database, removing a lot of the tooling and overhead required to get data into the system. As Rockset is purpose-built for real-time search and analytics, it has also been designed for field-level mutability, decreasing the CPU required to process inserts, updates and deletes.
In this blog, we’ll compare and contrast how Elasticsearch and Rockset handle data ingestion as well as provide practical techniques for using these systems for real-time analytics.
Elasticsearch
Data Ingestion in Elasticsearch
While there are many ways to ingest data into Elasticsearch, we cover three common methods for real-time search and analytics:
-
Ingest data from a relational database into Elasticsearch using the Logstash JDBC input plugin
-
Ingest data from Kafka into Elasticsearch using the Kafka Elasticsearch Service Sink Connector
-
Ingest data directly from the application into Elasticsearch using the REST API and client libraries
Ingest data from a relational database into Elasticsearch using the Logstash JDBC input plugin. The Logstash JDBC input plugin can be used to offload data from a relational database like PostgreSQL or MySQL to Elasticsearch for search and analytics.
Logstash is an event processing pipeline that ingests and transforms data before sending it to Elasticsearch. Logstash offers a JDBC input plugin that polls a relational database, like PostgreSQL or MySQL, for inserts and updates periodically. To use this service, your relational database needs to provide timestamped records that can be read by Logstash to determine which changes have occurred.
This ingestion approach works well for inserts and updates but additional considerations are needed for deletions. That’s because it’s not possible for Logstash to determine what’s been deleted in your OLTP database. Users can get around this limitation by implementing soft deletes, where a flag is applied to the deleted record and that’s used to filter out data at query time. Or, they can periodically scan their relational database to get access to the most up to date records and reindex the data in Elasticsearch.
Ingest data from Kafka into Elasticsearch using the Kafka Elasticsearch Sink Connector .It’s also common to use an event streaming platform like Kafka to send data from source systems into Elasticsearch for real-time search and analytics.
Confluent and Elastic partnered in the release of the Kafka Elasticsearch Service Sink Connector, available to companies using both the managed Confluent Kafka and Elastic Elasticsearch offerings. The connector does require installing and managing additional tooling, Kafka Connect.
Using the connector, you can map each topic in Kafka to a single index type in Elasticsearch. If dynamic typing is used as the index type, then Elasticsearch does support some schema changes such as adding fields, removing fields and changing types.
One of the challenges that does arise in using Kafka is needing to reindex the data in Elasticsearch when you want to modify the analyzer, tokenizer or indexed fields. This is because the mapping cannot be changed once it is already defined. To perform a reindex of the data, you will need to double write to the original index and the new index, move the data from the original index to the new index and then stop the original connector job.
If you do not use managed services from Confluent or Elastic, you can use the open-source Kafka plugin for Logstash to send data to Elasticsearch.
Ingest data directly from the application into Elasticsearch using the REST API and client libraries Elasticsearch offers the ability to use supported client libraries including Java, Javascript, Ruby, Go, Python and more to ingest data via the REST API directly from your application. One of the challenges in using a client library is that it has to be configured to work with queueing and back-pressure in the case when Elasticsearch is unable to handle the ingest load. Without a queueing system in place, there is the potential for data loss into Elasticsearch.
Updates, Inserts and Deletes in Elasticsearch
Elasticsearch has an Update API that can be used to process updates and deletes. The Update API reduces the number of network trips and potential for version conflicts. The Update API retrieves the existing document from the index, processes the change and then indexes the data again. That said, Elasticsearch does not offer in-place updates or deletes. So, the entire document still must be reindexed, a CPU intensive operation.
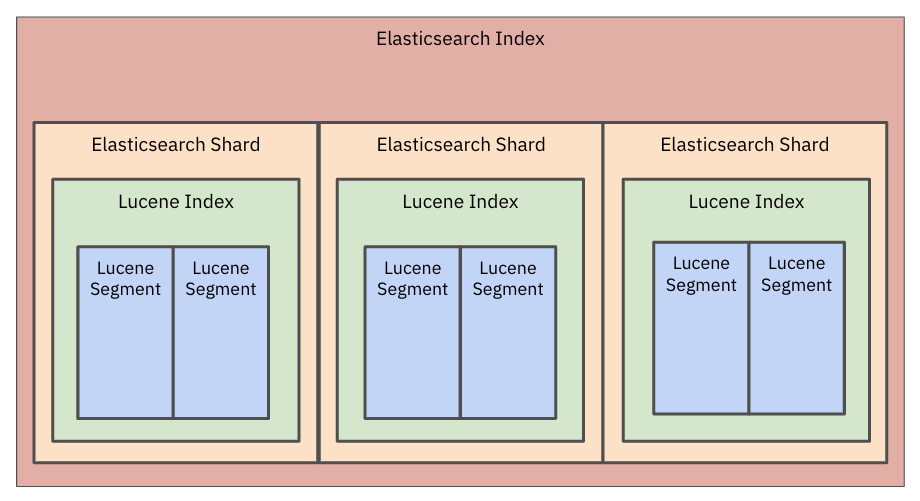
Under the hood, Elasticsearch data is stored in a Lucene index and that index is broken down into smaller segments. Each segment is immutable so documents cannot be changed. When an update is made, the old document is marked for deletion and a new document is merged to form a new segment. In order to use the updated document, all of the analyzers need to be run which can also increase CPU usage. It’s common for customers with constantly changing data to see index merges eat up a considerable amount of their overall Elasticsearch compute bill.
Given the amount of resources required, Elastic recommends limiting the number of updates into Elasticsearch. A reference customer of Elasticsearch, Bol.com, used Elasticsearch for site search as part of their e-commerce platform. Bol.com had roughly 700K updates per day made to their offerings including content, pricing and availability changes. They originally wanted a solution that stayed in sync with any changes as they occurred. But, given the impact of updates on Elasticsearch system performance, they opted to allow for 15-20 minute delays. The batching of documents into Elasticsearch ensured consistent query performance.
Deletions and Segment Merge Challenges in Elasticsearch
In Elasticsearch, there can be challenges related to the deletion of old documents and the reclaiming of space.
Elasticsearch completes a segment merge in the background when there are a large number of segments in an index or there are a lot of documents in a segment that are marked for deletion. A segment merge is when documents are copied from existing segments into a newly formed segment and the remaining segments are deleted. Unfortunately, Lucene is not good at sizing the segments that need to be merged, potentially creating uneven segments that impact performance and stability.
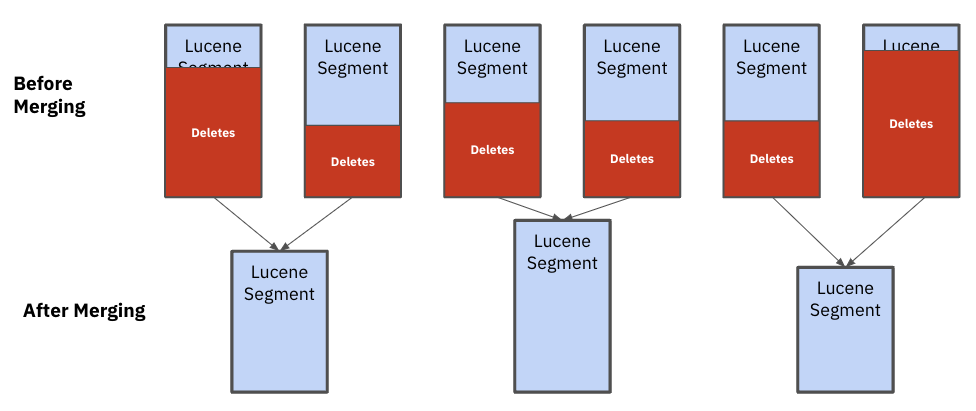
That’s because Elasticsearch assumes all documents are uniformly sized and makes merge decisions based on the number of documents deleted. When dealing with heterogeneous document sizes, as is often the case in multi-tenant applications, some segments will grow faster in size than others, slowing down performance for the largest customers on the application. In these cases, the only remedy is to reindex a large amount of data.
Replica Challenges in Elasticsearch
Elasticsearch uses a primary-backup model for replication. The primary replica processes an incoming write operation and then forwards the operation to its replicas. Each replica receives this operation and re-indexes the data locally again. This means that every replica independently spends costly compute resources to re-index the same document over and over again. If there are n replicas, Elastic would spend n times the cpu to index the same document. This can exacerbate the amount of data that needs to be reindexed when an update or insert occurs.
Bulk API and Queue Challenges in Elasticsearch
While you can use the Update API in Elasticsearch, it’s generally recommended to batch frequent changes using the Bulk API. When using the Bulk API, engineering teams will often need to create and manage a queue to streamline updates into the system.
A queue is independent of Elasticsearch and will need to be configured and managed. The queue will consolidate the inserts, updates and deletes to the system within a specific time interval, say 15 minutes, to limit the impact on Elasticsearch. The queuing system will also apply a throttle when the rate of insertion is high to ensure application stability. While queues are helpful for updates, they are not good at determining when there are a lot of data changes that require a full reindex of the data. This can occur at any time if there are a lot of updates to the system. It's common for teams running Elastic at scale to have dedicated operations members managing and tuning their queues on a daily basis.
Reindexing in Elasticsearch
As mentioned in the previous section, when there are a slew of updates or you need to change the index mappings then a reindex of data occurs. Reindexing is error prone and does have the potential to take down a cluster. What’s even more frightful, is that reindexing can happen at any time.
If you do want to change your mappings, you have more control over the time that reindexing occurs. Elasticsearch has a reindex API to create a new index and an Aliases API to ensure that there is no downtime when a new index is being created. With an alias API, queries are routed to the alias, or the old index, as the new index is being created. When the new index is ready, the aliases API will convert to read data from the new index.
With the aliases API, it is still tricky to keep the new index in sync with the latest data. That’s because Elasticsearch can only write data to one index. So, you will need to configure the data pipeline upstream to double write into the new and the old index.
Rockset
Data Ingestion in Rockset
Rockset uses built-in connectors to keep your data in sync with source systems. Rockset’s managed connectors are tuned for each type of data source so that data can be ingested and made queryable within 2 seconds. This avoids manual pipelines that add latency or can only ingest data in micro-batches, say every 15 minutes.
At a high level, Rockset offers built-in connectors to OLTP databases, data streams and data lakes and warehouses. Here’s how they work:
Built-In Connectors to OLTP Databases Rockset does an initial scan of your tables in your OLTP database and then uses CDC streams to stay in sync with the latest data, with data being made available for querying within 2 seconds of when it was generated by the source system.
Built-In Connectors to Data Streams With data streams like Kafka or Kinesis, Rockset continuously ingests any new topics using a pull-based integration that requires no tuning in Kafka or Kinesis.
Built-In Connectors to Data Lakes and Warehouses Rockset constantly monitors for updates and ingests any new objects from data lakes like S3 buckets. We generally find that teams want to join real-time streams with data from their data lakes for real-time analytics.
Updates, Inserts and Deletes in Rockset
Rockset has a distributed architecture optimized to efficiently index data in parallel across multiple machines.
Rockset is a document-sharded database, so it writes entire documents to a single machine, rather than splitting it apart and sending the different fields to different machines. Because of this, it’s quick to add new documents for inserts or locate existing documents, based on primary key _id for updates and deletes.
Similar to Elasticsearch, Rockset uses indexes to quickly and efficiently retrieve data when it is queried. Unlike other databases or search engines though, Rockset indexes data at ingest time in a Converged Index, an index that combines a column store, search index and row store. The Converged Index stores all of the values in the fields as a series of key-value pairs. In the example below you can see a document and then how it is stored in Rockset.

Under the hood, Rockset uses RocksDB, a high-performance key-value store that makes mutations trivial. RocksDB supports atomic writes and deletes across different keys. If an update comes in for the name field of a document, exactly 3 keys need to be updated, one per index. Indexes for other fields in the document are unaffected, meaning Rockset can efficiently process updates instead of wasting cycles updating indexes for entire documents every time.
Nested documents and arrays are also first-class data types in Rockset, meaning the same update process applies to them as well, making Rockset well suited for updates on data stored in modern formats like JSON and Avro.
The team at Rockset has also built several custom extensions for RocksDB to handle high writes and heavy reads, a common pattern in real-time analytics workloads. One of those extensions is remote compactions which introduces a clean separation of query compute and indexing compute to RocksDB Cloud. This enables Rockset to avoid writes interfering with reads. Due to these enhancements, Rockset can scale its writes according to customers’ needs and make fresh data available for querying even as mutations occur in the background.
Updates, Inserts and Deletes Using the Rockset API
Users of Rockset can use the default _id field or specify a specific field to be the primary key. This field enables a document or a part of a document to be overwritten. The difference between Rockset and Elasticsearch is that Rockset can update the value of an individual field without requiring an entire document to be reindexed.
To update existing documents in a collection using the Rockset API, you can make requests to the Patch Documents endpoint. For each existing document you wish to update, you just specify the _id field and a list of patch operations to be applied to the document.
The Rockset API also exposes an Add Documents endpoint so that you can insert data directly into your collections from your application code. To delete existing documents, simply specify the _id fields of the documents you wish to remove and make a request to the Delete Documents endpoint of the Rockset API.
Handling Replicas in Rockset
Unlike in Elasticsearch, only one replica in Rockset does the indexing and compaction using RocksDB remote compactions. This reduces the amount of CPU required for indexing, especially when multiple replicas are being used for durability.
Reindexing in Rockset
At ingest time in Rockset, you can use an ingest transformation to specify the desired data transformations to apply on your raw source data. If you wish to change the ingest transformation at a later date, you will need to reindex your data.
That said, Rockset enables schemaless ingest and dynamically types the values of every field of data. If the size and shape of the data or queries change, Rockset will continue to be performant and not require data to be reindexed.
Rockset can scale to hundreds of terabytes of data without ever needing to be reindexed. This goes back to the sharding strategy of Rockset. When the compute that a customer allocates in their Virtual Instance increases, a subset of shards are shuffled to achieve a better distribution across the cluster, allowing for more parallelized, faster indexing and query execution. As a result, reindexing does not need to occur in these scenarios.
Conclusion
Elasticsearch was designed for log analytics where data is not being frequently updated, inserted or deleted. Over time, teams have expanded their use for Elasticsearch, often using Elasticsearch as a secondary data store and indexing engine for real-time analytics on constantly changing transactional data. This can be a costly endeavor, especially for teams optimizing for real-time ingestion of data as well as involve a considerable amount of management overhead.
Rockset, on the other hand, was designed for real-time analytics and to make new data available for querying within 2 seconds of when it was generated. To solve this use case, Rockset supports in-place inserts, updates and deletes, saving on compute and limiting the use of reindexing of documents. Rockset also recognizes the management overhead of connectors and ingestion and takes a platform approach, incorporating real-time connectors into its cloud offering.
Overall, we’ve seen companies that migrate from Elasticsearch to Rockset for real-time analytics save 44% just on their compute bill. Join the wave of engineering teams switching from Elasticsearch to Rockset in days. Start your free trial today.