
Authors:
(1) Mingjie Liu, NVIDIA {Equal contribution};
(2) Teodor-Dumitru Ene, NVIDIA {Equal contribution};
(3) Robert Kirby, NVIDIA {Equal contribution};
(4) Chris Cheng, NVIDIA {Equal contribution};
(5) Nathaniel Pinckney, NVIDIA {Equal contribution};
(6) Rongjian Liang, NVIDIA {Equal contribution};
(7) Jonah Alben, NVIDIA;
(8) Himyanshu Anand, NVIDIA;
(9) Sanmitra Banerjee, NVIDIA;
(10) Ismet Bayraktaroglu, NVIDIA;
(11) Bonita Bhaskaran, NVIDIA;
(12) Bryan Catanzaro, NVIDIA;
(13) Arjun Chaudhuri, NVIDIA;
(14) Sharon Clay, NVIDIA;
(15) Bill Dally, NVIDIA;
(16) Laura Dang, NVIDIA;
(17) Parikshit Deshpande, NVIDIA;
(18) Siddhanth Dhodhi, NVIDIA;
(19) Sameer Halepete, NVIDIA;
(20) Eric Hill, NVIDIA;
(21) Jiashang Hu, NVIDIA;
(22) Sumit Jain, NVIDIA;
(23) Brucek Khailany, NVIDIA;
(24) George Kokai, NVIDIA;
(25) Kishor Kunal, NVIDIA;
(26) Xiaowei Li, NVIDIA;
(27) Charley Lind, NVIDIA;
(28) Hao Liu, NVIDIA;
(29) Stuart Oberman, NVIDIA;
(30) Sujeet Omar, NVIDIA;
(31) Sreedhar Pratty, NVIDIA;
(23) Jonathan Raiman, NVIDIA;
(33) Ambar Sarkar, NVIDIA;
(34) Zhengjiang Shao, NVIDIA;
(35) Hanfei Sun, NVIDIA;
(36) Pratik P Suthar, NVIDIA;
(37) Varun Tej, NVIDIA;
(38) Walker Turner, NVIDIA;
(39) Kaizhe Xu, NVIDIA;
(40) Haoxing Ren, NVIDIA.
Table of Links
- Abstract and Intro
- Dataset
- ChipNemo Domain Adaptation Methods
- LLM Applications
- Evaluations
- Discussion
- Related Works
- Conclusions
- Acknowledgments, Contributions and References
- Appendix
APPENDIX
A. Data Collection Process
Collection was implemented with a set of shell and Python scripts, designed to identify relevant design data and documentation, convert them to plain text if applicable, filter them using basic quality metrics, compute a checksum for precise file deduplication, and compress them for storage. The collection flow did not use off-the-shelf LLM-specific scraping and collection scripts, as we aimed to minimize space requirements through in-situ data collection of internal data sources (both networked file systems and internal web applications). For file system-based collection, data was kept in-place while being filtered for quality, instead of storing additional sets of raw data locally.
The design and verification data collection encompassed a variety of source files, including Verilog and VHDL (RTL and netlists), C++, Spice, Tcl, various scripting languages, and build-related configuration files. Data from internal web services were gathered through both REST API calls and conventional crawling, with HTML formatting being removed using the open-source BeautifulSoup [52] Python library in both instances to minimize inadvertent removal of coding examples, at the cost of introducing more boiler plate navigation bars and other HTML page elements. Our data collection flow supported conventional documentation formats, including .docx, .pptx, and .pdf, using readily available Python conversion libraries and open-source tools.
As most internal data is believe to be of high quality, minimal filtering was applied: line count filtering was used to ensure that exceedingly large or small files were excluded, and files were sorted into broad categories of manually written versus tool-generated.
B. Domain Adaptive Pretraining (DAPT)
In this section we present detailed results on our domain adaptive pretrained models. We also detail our ablation experiments on domain adaptive pretraining.
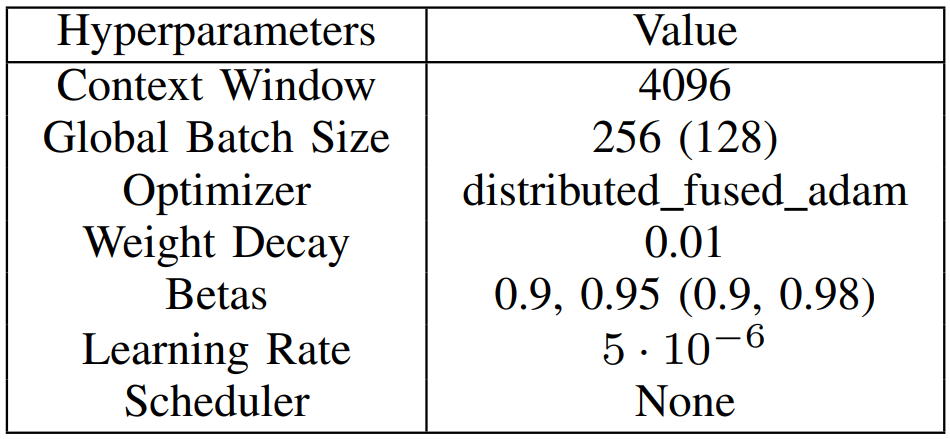
DAPT Hyperparameters: Details presented in Table VI.
Auto Eval Results: We present detailed results on auto evaluation benchmarks in Table VII and Table VIII. For simplicity, in the remainders of the section we present aggregated benchmark results for ablation studies:
• Chip: We report average results on in-domain Design, Scripting, Bugs, and Circuits benchmarks from Table III (5-shot).
• MMLU: We report the overall results on MMLU (5- shot) [22] a popular aggregated benchmark on a wide variety of subjects.
• Reasoning: We report average results on popular public benchmarks on common sense reasoning (0-shot), including Winogrande [53], hellaswag [54], ARC-easy [55], and RACE-High [56].
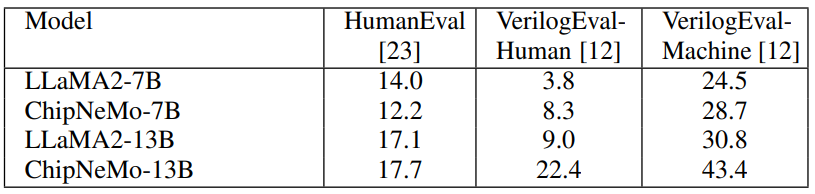
• Code: We report average pass-rate of coding benchmarks with greedy decoding, including HumanEval [23], VerilogEval-Machine [12], and VerilogEval-Human [12].
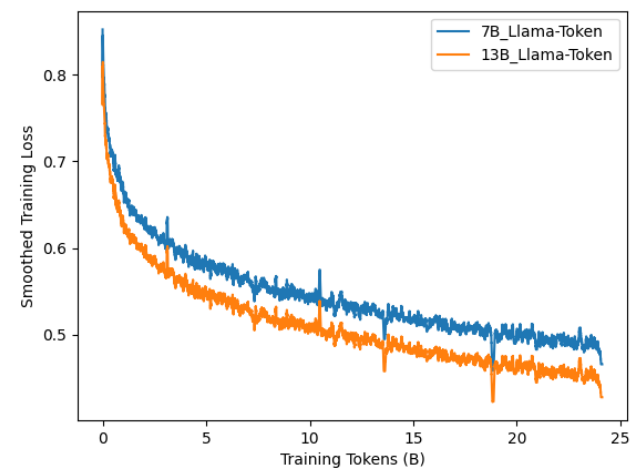
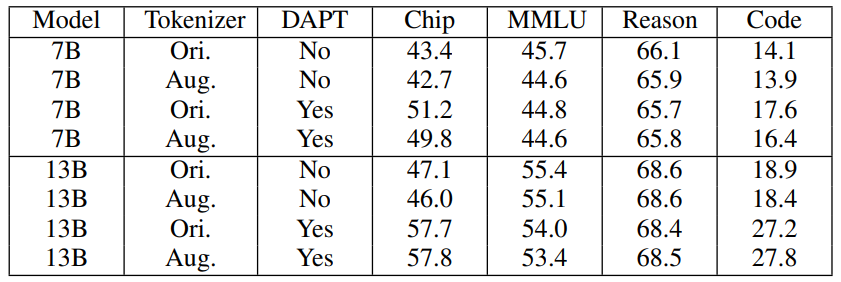
Tokenizer Augmentation: We experimented with DAPT using the original LLaMA2 tokenizer and the augmented tokenizer as described in Section III-A. Figure 11 depicts smoothed training loss for ChipNeMo with the original unmodified tokenizer. When compared with Figure 2, we observe that an augmented tokenizer has larger training loss upon initialization, due to added tokens never being observed during foundation model pretraining. Similar training loss is achieved for DAPT with 1 epoch.
Table IX presents aggregated auto evaluation benchmark results. We note that careful tokenizer augmentation and weight initialization only slightly impacts model performance on general academic benchmarks. DAPT significantly improved domain benchmarks with any tokenizer, including Verilog coding (no major difference in HumanEval). We conclude that augmenting the tokenizer comes with the benefit of improved tokenizer and training efficiency with no degradation on the models general language and domain capabilities.
Public Datasets Mix-in: As introduced in Section II-A we included public data in DAPT, sampled from commonlyused public datasets for foundation model pre-training. We primarily hoped that mixing in public data such as Wikipedia in DAPT could help “correct” disturbances brought by tokenizer augmentation and improve general natural language capabilities
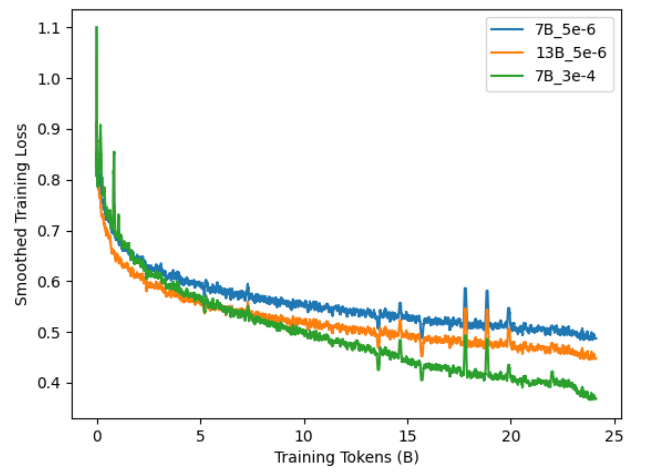
of models. We conducted another round of DAPT with tokenizer augmentation using only the domain data, training for the same number of steps equating to roughly 1.1 epoch of the data. We found that public data mix-in slightly improves results. We present detailed results in Table X.

Figure 12 shows the training loss for ChipNeMo-7B with augmented tokenizers including public dataset mix-in. We observed large spikes in training loss at the initial training steps with the final training loss for 7B models to even be better than 13B original DAPT hyperparameters. However, we note substantial degradation across natural language benchmarks as shown in Table XII, including in-domain chip design. Coding capabilities improved as consistent with the findings of [32].
We highlight that our case differs from that in [32]. Although we also conduct “continued pretraining” initializing from pretrained checkpoints, we preferably want the model to maintain high degrees of performance on general capabilities, while

distilling domain dataset information and knowledge (unseen in model pretraining) into model weights. In contrast, [32] use publicly available code data that predominantly lacks natural language elements, emphasizing their primary focus on coding-related tasks. We hypothesize that a smaller learning rate played a dual role for domain adaptation, facilitating the distillation of domain knowledge through DAPT while maintaining a balance that did not veer too far from the base model, thus preserving general natural language capabilities while significantly improving performance on in-domain tasks
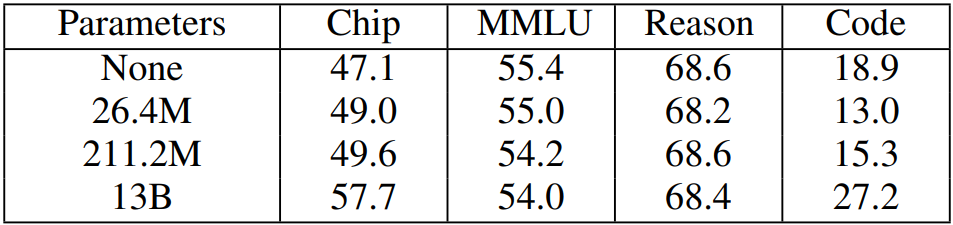
Parameter Efficient Fine-Tuning (PEFT): Parameter efficient fine-tuning freezes the pre-trained model weights and injects trainable parameters in smaller adapter models for efficient fine-tuning of downstream tasks. We explore the use of PEFT in DAPT using Low-Rank Adaptation (LoRA) [16]. Since our transformer layer implementation fuses KQV into a single projection, we add LoRA adapters for a single Low-Rank projection for each self attention layer in combined fashion. We experiment on LLaMA2-13B models with the original LLaMA2 tokenizer, using the same DAPT training setups in Table VI. We ran two experiments, introducing additional trainable parameters of 26.4 million (small) and 211.2 million (large) respectively.
Figure 13 shows the training loss curves of LoRA models and compares with full parameter training. For both LoRA models, the loss quickly converges and stops decreasing beyond a certain point. Table XIII reports the evaluation results on LoRA models. Both LoRA models significantly underperforms full parameter training on in-domain chip design tasks. LoRA models improve in chip design tasks compared to their nonDAPT counterparts, with the larger model exhibiting slightly better (but non significant) results.

![TABLE XI: Training Hyperparameters with Larger Learning Rate. We adopt similar parameter as to [32].](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-ftg3uoe.png)
C. Retrieval Model Training
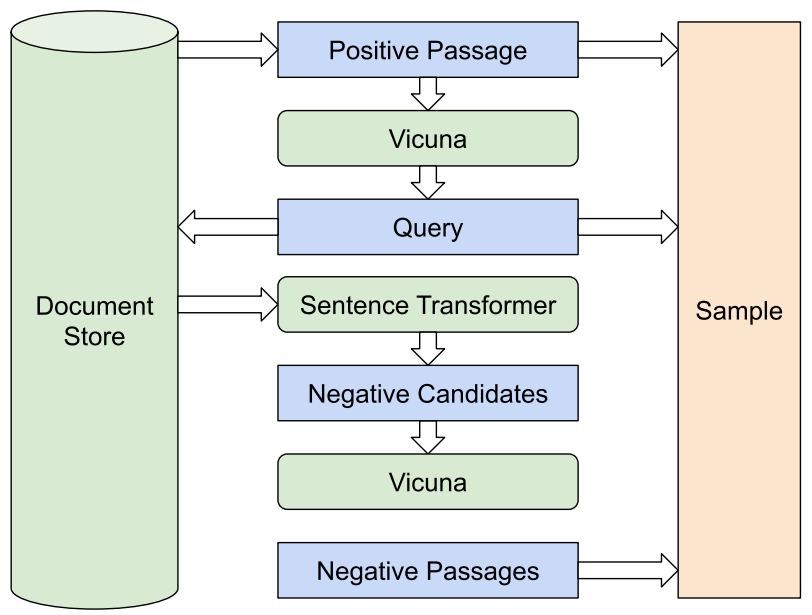
Manually generating training samples is very effort intensive, so we elected to implement a process to generate them automatically. Since we are using contrastive learning to finetune our model, each sample requires a set of both positive passages and negative passages, particularly hard negatives to maximize the accuracy.
1) Dataset Sampling Procedure: Figure 14 describes the steps taken to generate a sample:
• Step 1: Randomly select a passage from the document corpus
• Step 2: Use a language model (Vicuna) to generate a valid query from the passage
• Step 3: Use a pre-existing retrieval model (sentence transformer) to fetch the top-N passages from the document corpus for the query where each passage is a potential hard-negative
• Step 4: It is possible that some of the fetched passages are actually positive, so use the same language model to filter out the positive passages
• Step 5: If there are not enough negative passages after this filtering process, supplement with random passages from the corpus

![Fig. 13: Smoothed Training Loss of LoRA [16]. 13B corresponds to full parameter DAPT.](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-w7i3usg.png)
For our initial research we used Vicuna [4] and Sentence Transformer [33]; however, they can easily be replaced with LLaMA2 [5] and BM25 [42] respectively to produce a retrieval model that is commercially viable.
2) Hit Quality Comparison: Not all hits are created equal. The passage in the Spec example below clearly and completely answers its query. The passage in the Build example contains the answer; however, more context is required to answer the query.
Spec Example: Hit passage clearly answers the query.

Build Example: Additional information is required to fully answer the query. Such as: What is a DL? How do we know Arch-Build-Hotseat-XXX is a DL?

D. Additional Evaluation Data
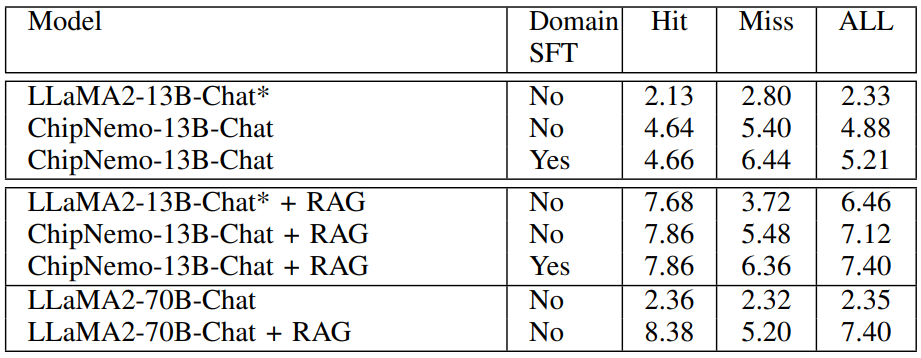
Table XIV shows the evaluation data for all models on the engineering assistant chatbot application.
Table XV shows our evaluation results for all models on the EDA script generation task.
Table XVI shows our evaluation results for all models on the bug summarization and analysis task.


E. Examples
1) Engineering Assistant Chatbot:



2) EDA Script Generation: Some function names and commands are obfuscated.


3) Bug Summary and Analysis: Usernames, chip names and paths are obfuscated.

This paper is available on arxiv under CC 4.0 license.